前端知识笔记
本文主要记录了关于前端面试常考与常问的知识笔记,内容较多,不间断更新。
CSS
CSS中盒模型有传统的content-box与border-box,二者区别在于前者的width与height设置的是content-box,而后者设置的是border-box,注意背景图之类的属性显示依然相同,默认的background-origin属性就是padding-box,即背景图从padding-box开始显示,注意这个属性不要与background-color混淆,background-color默认全部显示。CSS优先级ID选择器的个数。- 类选择器,属性选择器,伪类选择器的个数。
- 标签选择器,伪元素选择器的个数。
使用
rem的移动端适配方案核心思路为:
- 设置网页元素的
width属性为rem单位。 - 通过
js获取客户viewport宽度,并除以初始设置宽度,得到放大比例scale。 - 修改
html元素的font-size,达到等比例适配效果。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38<!DOCTYPE html> <html lang="zh-CN"> <head> <meta charset="UTF-8" /> <meta http-equiv="X-UA-Compatible" content="IE=edge" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <title>Document</title> <style> * { padding: 0; margin: 0; } .w-550px { width: 550rem; height: 100px; background-color: rgb(209, 255, 240); } .full { width: 750rem; height: 100px; background-color: rgb(195, 200, 199); } </style> </head> <body> <div class="w-550px"></div> <div class="full"></div> <script> function setRem() { // 当前页面宽度相对于 750 宽的缩放比例,可根据自己需要修改 const scale = document.documentElement.clientWidth / 750; document.documentElement.style.fontSize = scale + "px"; } setRem(); window.onresize = setRem; </script> </body> </html>确定浏览器窗口尺寸的使用方案
1
2
3
4
5
6
7
8
9var w = window.innerWidth || document.documentElement.clientWidth || document.body.clientWidth; var h = window.innerHeight || document.documentElement.clientHeight || document.body.clientHeight;- 设置网页元素的
DPI 的相关概念
DPI 的全称是 Dots Per Inch,意思是每英寸点数。它是一个度量单位,用于表示点阵数码影像的分辨率,也就是每一英寸长度中,取样、可显示或输出点的数目。DPI 也可以用来衡量打印机、鼠标等设备的分辨率,一般来说,DPI 值越高,表明设备的分辨率越高,图像的清晰度越高 。DPI 有以下几种应用场景:
- 图片 DPI:图片 DPI 是指每英寸的像素,类似于密度,即每英寸图片上的像素点数量,用来表示图片的清晰度。由于受网络传输速度的影响,web 上使用的图片都是 72dpi,但是冲洗照片不能使用这个参数,必须是 300dpi 或者更高 350dpi。
- 打印精度 DPI:打印精度 DPI 是指打印机在每英寸可打印的点数,至少应有 300dpi 的分辨率,才能使打印效果得到基本保证。打印尺寸、图像的像素数与打印分辨率之间的关系可以利用下列的计算公式加以表示:图像的横向(竖向)像素数=打印横向(竖向)分辨率 × 打印的横向(竖向)尺寸,图像的横向(竖向)像素数/打印横向(竖向)分辨率=打印的横向(竖向)尺寸。
- 鼠标 DPI:鼠标 DPI 是指鼠标的定位精度,单位是 dpi 或 cpi,指鼠标移动中,每移动一英寸能准确定位的最大信息数。DPI 是每英寸点数,也就是鼠标每移动一英寸指针在屏幕上移动的点数。比如 400DPI 的鼠标,他在移动一英寸的时候,屏幕上的指针可以移动 400 个点。鼠标 DPI 不是越高越好,不同的 DPI 适合不同的使用场景和用户习惯。
前端中 DPR 与 PPI 的相关概念
设备像素:即屏幕能够显示的最小像素,一般为屏幕的参数。
设备独立像素:即屏幕真正显示的像素,对于高分屏可能将几个像素点合为一个像素点显示。
DPR:device pixel ratio,即设备像素与设备独立像素的比值,可通过window.devicePixelRatio获取。
PPI:pixel per inch,即单位英寸数的像素点体积。BFC(Block Formatting Context):块级格式化上下文,可以创造出一处独立的空间,使得元素内部的影响不会到外部。
触发条件:html根元素。- 脱离文档流的元素,如浮动,定位里面的
absolute和fixed。 overflow属性不为visible,为hidden,scroll,auto。flex,inline-flex,grid,inline-grid,table,inline-table,inline-block。
作用:- 解决了子元素浮动父元素高度塌陷的的问题。
- 解决了
margin合并的问题。 - 自己不会被浮动元素所覆盖。
注意
BFC内部子元素的布局逻辑与正常文档流仍然相同,也就是仍然会出现margin塌陷等问题,BFC的作用主要是消除对开启BFC元素本身的影响。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43<style> .wrap { overflow: hidden; // 新的BFC } p { color: #f55; background: #fcc; width: 200px; line-height: 100px; text-align: center; margin: 100px; } </style> <body> <p>Haha</p> <div class="wrap"> <p>Hehe</p> </div> </body> <style> body { width: 300px; position: relative; } .aside { width: 100px; height: 150px; float: left; background: #f66; } .main { height: 200px; background: #fcc; overflow: hidden; } </style> <body> <div class="aside"></div> <div class="main"></div> </body>实现元素水平垂直居中的方式
行内元素或者行内块元素
注意
line-height倍数参考的是元素自身font-size的百分比。1
2
3
4
5span { height: 100px; line-height: 100px; vertical-align: middle; }块元素居中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100/* 利用定位 */ .father { position: relative; } .son { position: fixed; left: 0; right: 0; top: 0; bottom: 0; margin: auto; } /* 利用定位加上margin */ .father { position: relative; } .son { position: fixed; left: 50%; right: 50%; margin-left: -50px; margin-top: -50px; width: 100px; height: 100px; } /* 利用定位加上transform */ .father { position: relative; } .son { position: fixed; left: 50%; right: 50%; transform: translate(-50%, -50%); } /* 利用margin与maring-top */ .son { margin: 0 auto; margin-top: 父元素高度减子元素高度的一半; } /* table布局 */ .father { display: table-cell; width: 200px; height: 200px; background: skyblue; vertical-align: middle; text-align: center; } .son { display: inline-block; width: 100px; height: 100px; background: red; } /* flex布局 */ .father { display: flex; justify-content: center; align-items: center; width: 200px; height: 200px; background: skyblue; } .son { width: 100px; height: 100px; background: red; } .outer { width: 400px; height: 400px; background-color: #888; display: flex; } .inner { width: 100px; height: 100px; background-color: orange; margin: auto; } /* grid网格布局 */ .father { display: grid; align-items: center; justify-content: center; width: 200px; height: 200px; background: skyblue; } .son { width: 10px; height: 10px; border: 1px solid red; }
关于
flex数值属性统一设置的问题。有关快捷值:
auto (1 1 auto)和none (0 0 auto)- 只有一个非负值:视为
flex-grow的值,flex-shrink视为1,flex-basis视为0。 - 有两个非负值:视为
flex-grow与flex-shrink的值,flex-basis视为0。 - 一个非负值与一个百分数:视为
flex-grow与flex-basis的值,flex-shrink视为1。 - 当只有一个百分数或者长度的时候:视为
flex-basis的值,flex-grow为1,flex-shrink为1。
- 只有一个非负值:视为
grid布局1
2
3
4
5
6
7
8
9
10
11
12
13
14
15.wrapper { display: grid; /* 声明了三列,宽度分别为 200px 200px 200px */ grid-template-columns: 200px 200px 200px; grid-gap: 5px; /* 声明了两行,行高分别为 50px 50px */ grid-template-rows: 50px 50px; } /* 通过repeat减少重复代码 */ .wrapper { display: grid; grid-template-columns: repeat(3, 200px); grid-gap: 5px; grid-template-rows: repeat(2, 50px); }grid-template-columns: repeat(auto-fill, 200px)表示列宽是 200 px,但列的数量是不固定的,只要浏览器能够容纳得下,就可以放置元素grid-template-columns: 200px 1fr 2fr表示第一个列宽设置为 200px,后面剩余的宽度分为两部分,宽度分别为剩余宽度的 1/3 和 2/3minmax(100px, 1fr)表示列宽不小于 100px,不大于 1frgrid-template-columns: 100px auto 100px表示第一第三列为 100px,中间由浏览器决定长度grid-row-gap: 10px 表示行间距是 10px
grid-column-gap: 20px 表示列间距是 20px
grid-gap: 10px 20px 等同上述两个属性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15.container { display: grid; grid-template-columns: 100px 100px 100px; grid-template-rows: 100px 100px 100px; grid-template-areas: "a b c" "d e f" "g h i"; } /* 上面代码先划分出9个单元格,然后将其定名为a到i的九个区域,分别对应这九个单元格。 多个单元格合并成一个区域的写法如下 */ grid-template-areas: "a a a" "b b b" "c c c";如果某些区域不需要利用,则使用”点”(.)表示
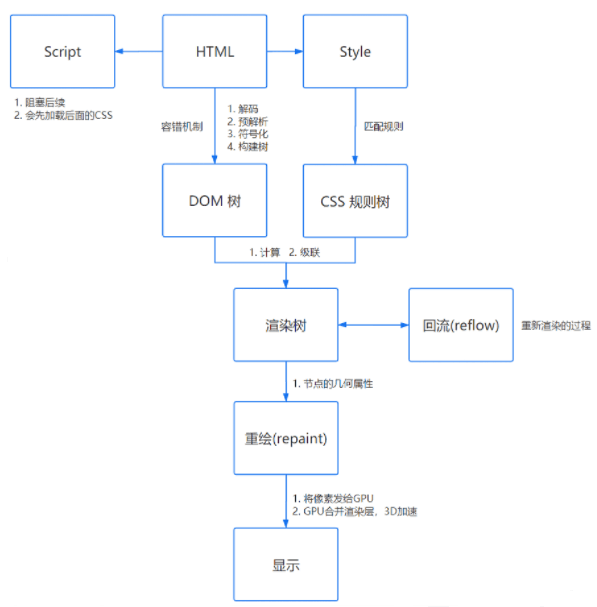
grid-auto-flow类似flex-direction,设置横向排列还是纵向排列。如何理解回流与重绘
解析 HTML,生成 DOM 树,解析 CSS,生成 CSSOM 树将 DOM 树和 CSSOM 树结合,生成渲染树(Render Tree)
Layout(回流):根据生成的渲染树,进行回流(Layout),得到节点的几何信息(位置,大小)
Painting(重绘):根据渲染树以及回流得到的几何信息,得到节点的绝对像素
Display:将像素发送给 GPU,展示在页面上
优化手段:尽量使用类名,不使用内联的样式,使用
fixed与absolute定位。脱离文档流减少对其他元素的影响。使用transform,opacity,filter等做动画,效率更高css性能优化- 首屏内联关键
css:防止外部导入css阻塞html显示。 - 资源压缩,异步加载。
- 避免使用昂贵的
CSS属性,例如border-radius。
- 首屏内联关键
文本超出省略显示
1
2
3
4
5.line { overflow: hidden; white-space: nowrap; text-overflow: ellipsis; }使用
CSS画一个三角形1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21<!DOCTYPE html> <html lang="zh-CN"> <head> <meta charset="UTF-8" /> <meta http-equiv="X-UA-Compatible" content="IE=edge" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <title>Document</title> <style> .border { border-style: solid; width: 0; height: 0; border-width: 0 25px 25px; border-color: transparent transparent #ffad60; } </style> </head> <body> <div class="border"></div> </body> </html>使用
flex实现一个九宫格布局。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38<!DOCTYPE html> <html lang="zh-CN"> <head> <meta charset="UTF-8" /> <meta http-equiv="X-UA-Compatible" content="IE=edge" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <title>Document</title> <style> .container { display: flex; flex-wrap: wrap; width: 304px; height: 304px; justify-content: space-evenly; align-content: space-evenly; background-color: black; } .container > .item { width: 100px; height: 100px; background-color: white; } </style> </head> <body> <div class="container"> <div class="item"></div> <div class="item"></div> <div class="item"></div> <div class="item"></div> <div class="item"></div> <div class="item"></div> <div class="item"></div> <div class="item"></div> <div class="item"></div> </div> </body> </html>sass变量
需要注意的是
sass中变量也有作用域1
2
3
4
5
6
7
8
9
10
11// sass的变量声明 $highlight-color: #f90; $highlight-border: 1px solid $highlight-color; .selected { border: $highlight-border; } //编译后 .selected { border: 1px solid #f90; }嵌套
css规则1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107#content { article { h1 { color: #333; } p { margin-bottom: 1.4em; } } aside { background-color: #eee; } } /* 编译后 */ #content article h1 { color: #333; } #content article p { margin-bottom: 1.4em; } #content aside { background-color: #eee; } // 对于伪类元素需要使用父选择器的标识符 article a { color: blue; &:hover { color: red; } } // 编译后 article a { color: blue; } article a:hover { color: red; } // 群组选择器的嵌套 .container { h1, h2, h3 { margin-bottom: 0.8em; } } nav, aside { a { color: blue; } } // 子组合选择器,和同层选择器 article { ~ article { border-top: 1px dashed #ccc; } > section { background: #eee; } dl > { dt { color: #333; } dd { color: #555; } } nav + & { margin-top: 0; } } article ~ article { border-top: 1px dashed #ccc; } article > footer { background: #eee; } article dl > dt { color: #333; } article dl > dd { color: #555; } nav + article { margin-top: 0; } // 嵌套属性 nav { border: 1px solid #ccc { left: 0px; right: 0px; } } nav { border: 1px solid #ccc; border-left: 0px; border-right: 0px; }混合器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23// 混合器中不仅可以包含属性,也可以包含css规则,包含选择器和选择器中的属性 @mixin no-bullets { list-style: none; li { list-style-image: none; list-style-type: none; margin-left: 0px; } } ul.plain { color: #444; @include no-bullets; } ul.plain { color: #444; list-style: none; } ul.plain li { list-style-image: none; list-style-type: none; margin-left: 0px; }
JS
谈谈对闭包的理解
闭包是一个函数可以记住并访问它的词法作用域,即时这个函数在这个变量的作用域外执行。换言之,即闭包为函数和它的外部变量的组合。
其作用有:
- 创建私有变量。
- 延长变量的声明周期。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
// 防抖
const debounce = (func, delay, immediate) => {
let timer = null;
return function (...params) {
if (timer) clearTimeout(timer);
else if (immediate) func.apply(this, params);
timer = setTimeout(() => {
func.apply(this, params);
timer = null;
}, delay);
};
};
// 节流
const throttle = (func, delay, immediate) => {
let startTime = 0;
let timer = null;
return function (...params) {
if (!startTime) startTime = Date.now();
const remainTime = delay - (Date.now() - startTime);
if (remainTime > 0) {
if (timer) clearTimeout(timer);
else if (immediate) func.apply(this, params);
timer = setTimeout(() => {
func.apply(this, params);
timer = null;
startTime = 0;
}, remainTime);
}
};
};循环递归深拷贝
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
function deepClone(obj, hash = new WeakMap()) {
if (obj === null) return obj; // 如果是null或者undefined我就不进行拷贝操作
if (obj instanceof Date) return new Date(obj);
if (obj instanceof RegExp) return new RegExp(obj);
// 可能是对象或者普通的值 如果是函数的话是不需要深拷贝
if (typeof obj !== "object") return obj;
// 是对象的话就要进行深拷贝
if (hash.get(obj)) return hash.get(obj);
let cloneObj = new obj.constructor();
// 找到的是所属类原型上的constructor,而原型上的 constructor指向的是当前类本身
hash.set(obj, cloneObj);
for (let key in obj) {
if (obj.hasOwnProperty(key)) {
// 实现一个递归拷贝
cloneObj[key] = deepClone(obj[key], hash);
}
}
return cloneObj;
}作用域与执行上下文
作用域
作用域指的是变量与函数的可访问范围。JS有三种类型的作用域- 全局作用域
- 函数作用域
- 块级作用域
JS中的作用域链是指在查找变量时沿着作用域层级所形成的链条,它由当前执行上下文及其所有父级执行上下文的变量对象组成。执行上下文
执行上下文指的是代码运行时的环境- 全局执行上下文
- 函数执行上下文
eval执行上下文。
代码的执行过程
- 当执行全局代码时,会创建一个全局执行上下文,并将其压入执行栈。
- 当执行全局代码中的一个函数时,会创建一个函数执行上下文,并将其压入执行栈。
- 在函数执行上下文中,会先创建一个变量对象,并初始化其中的变量和函数声明。
- 然后会创建一个作用域链,并将当前变量对象添加到作用域链的最前端。
- 接着会确定
this值,并将其赋值给当前执行上下文。 - 最后会逐行执行函数内部的代码,并根据作用域链来访问和操作变量和函数。
实现一个严格相等符(===)
先判断类型再判断值是否相等
1
2
3
4
5
6
7
8
9
10
11
const getType = (variable) => {
const type = typeof variable;
if (type !== "object") return type;
return Object.prototype.toString
.call(variable)
.match(/^\[Object (\w+)\]$/)[1]
.toLowerCase();
};
const strictEqual = (left, right) => {
return getType(left) == getType(right) && left == right;
};Ajax
封装一个简单的
ajax请求1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33//封装一个ajax请求 function ajax(options) { //创建XMLHttpRequest对象 const xhr = new XMLHttpRequest(); //初始化参数的内容 options = options || {}; options.type = (options.type || "GET").toUpperCase(); options.dataType = options.dataType || "json"; const params = options.data; //发送请求 if (options.type === "GET") { xhr.open("GET", options.url + "?" + params, true); xhr.send(null); } else if (options.type === "POST") { xhr.open("POST", options.url, true); xhr.send(params); //接收请求 xhr.onreadystatechange = function () { if (xhr.readyState === 4) { let status = xhr.status; if (status >= 200 && status < 300) { options.success && options.success(xhr.responseText, xhr.responseXML); } else { options.fail && options.fail(status); } } }; } }使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14ajax({ type: "post", dataType: "json", data: {}, url: "https://xxxx", success: function (text, xml) { //请求成功后的回调函数 console.log(text); }, fail: function (status) { ////请求失败后的回调函数 console.log(status); }, });
原型链
原型链的尽头
Function → Function.prototype → Object.prototype → nullObject → Function.prototype → Object.prototype → null
通过隐式绑定 this
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
Function.prototype.myCall = function (obj, ...params) {
const key = Symbol("key");
obj[key] = this;
const result = obj[key](...params);
delete obj[key];
return result;
};
Function.prototype.myApply = function (obj, params) {
const key = Symbol("key");
obj[key] = this;
const result = obj[key](...params);
delete obj[key];
return result;
};
Function.prototype.myBind = function (obj, ...params) {
let func = this;
const bound = function (...args) {
const isNew = Boolean(new.target);
const isValue = isNew ? this : obj;
func.myApply(isValue, [...params, ...args]);
};
if (func.prototype) {
bound.prototype = Object.create(func.prototype);
}
return bound;
};instanceof 函数手写实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
const myInstanceOf = (left, right) => {
if (
left === null ||
(typeof left !== "object" && typeof left !== "function") ||
typeof right !== "function"
)
return false;
const proto = Object.getPrototypeOf(left);
while (true) {
if (proto === null) return false;
if (proto === right.prototype) return true;
proto = Object.getPrototypeOf(proto);
}
};
class Name {}
const name1 = new Name();
console.log(myInstanceOf(name1, Name));
console.log(myInstanceOf(Name, Function));new 操作符手写实现
1
2
3
4
5
const newFunc = (constructor, ...params) => {
const obj = Object.create(constructor.prototype);
const result = constructor.apply(obj, params);
return typeof result === "object" && result !== null ? result : obj;
};XSS 攻击
XSS(Cross Site Scripting),跨站脚本攻击,允许攻击者将恶意代码植入到提供给其它用户使用的页面中
- 储存型:恶意代码提交到对应数据库,用户请求拼接在
html中返回。 - 反射型:
url拼接参数,服务端返回恶意代码。 DOM型:js的自身漏洞,利用js插入恶意代码。
储存型和反射型都是服务端漏洞,DOM型是前端JS的漏洞。
解决手段
- 对用户的输入进行合法性检查和过滤,避免接受或存储包含恶意脚本的数据。
- 对用户的输出进行转义或编码,避免浏览器将输出的数据当作脚本来执行。
- 使用
HTTP头部的Content-Security-Policy来限制浏览器加载或执行的资源,避免加载或执行来自不可信来源的脚本。 - 使用
HTTP头部的X-XSS-Protection来启用浏览器的XSS防护功能,避免浏览器执行检测到的XSS攻击。 - 使用其他的安全措施,比如
HTTPS、HTTPOnly、SameSite等,来增强用户的安全性和隐私性。
CSRF 攻击
CSRF(Cross Site Request Forgery)攻击是一种利用用户在已登录的网站上执行非本意的操作的攻击方法。
CSRF 攻击的原理是,攻击者构造一个包含恶意请求的网页或链接,然后诱使用户访问这个网页或链接。当用户访问时,浏览器会自动携带用户在目标网站的 cookie 信息,从而使得恶意请求看起来像是用户自己发出的。如果目标网站没有对请求进行有效的验证,就会执行恶意请求的操作,比如转账、修改密码、删除数据等。
CSRF 攻击的危害是非常严重的,它可以导致用户的隐私泄露、账号被盗、财产损失、甚至被控制或劫持。
CSRF 攻击的防御方法主要有以下几种:
- 验证
HTTP Referer字段,检查请求是否来自合法的来源。 - 在非
GET请求中增加token或验证码,并在服务器端验证其有效性。 - 使用
SameSite属性来限制浏览器发送跨站请求时携带的cookie信息。 - 使用其他的安全措施,比如
HTTPS、CORS、X-Frame-Options等,来增强用户的安全性和隐私性。
断点续传的大致思路
服务端到客户端。下载类似(IDM,与 Aria2 等工具)
断点续传是一种文件传输技术,它可以在网络中断或其他异常情况下,从上次传输的位置继续传输文件,而不是从头开始。断点续传的原理是利用 HTTP 协议中的 Range 和 Content-Range 头,以及 Etag 或 Last-Modified 头,来指定文件的分片范围和校验文件的唯一性。断点续传的步骤如下:- 客户端向服务器发送一个带有 Range 头的请求,指定要获取的文件的部分内容,例如:
Range: bytes=500-999表示请求第 500-999 字节的内容。 - 服务器收到请求后,判断是否支持断点续传,如果支持,就返回相应的分片内容和状态码 206,以及 Content-Range 头,指定返回的分片范围和文件总大小,例如:
Content-Range: bytes 500-999/22400表示返回的是第 500-999 字节的内容,文件总大小为 22400 字节。 - 客户端收到分片内容后,将其拼接到已经下载的部分,然后继续发送下一个分片的请求,直到文件下载完成。
- 在下载过程中,如果发生中断,客户端可以记录已经下载的分片范围,然后在恢复下载时,从下一个分片开始请求。
- 为了避免文件在服务器端发生变化,导致下载的内容不一致,客户端可以在请求时带上 If-Range 头,指定文件的 Etag 或 Last-Modified 值,用于校验文件的唯一性。如果文件没有变化,服务器会继续返回分片内容,如果文件发生变化,服务器会返回整个文件和状态码 200。
- 客户端向服务器发送一个带有 Range 头的请求,指定要获取的文件的部分内容,例如:
客户端到服务端。
分片上传
分片上传,就是将所要上传的文件,按照一定的大小,将整个文件分隔成多个数据块(Part)来进行分片上传
大致流程如下:- 将需要上传的文件按照一定的分割规则,分割成相同大小的数据块;
- 初始化一个分片上传任务,返回本次分片上传唯一标识;
- 按照一定的策略(串行或并行)发送各个分片数据块;
- 发送完成后,服务端根据判断数据上传是否完整,如果完整,则进行数据块合成得到原始文件
断点续传
断点续传指的是在下载或上传时,将下载或上传任务人为的划分为几个部分每一个部分采用一个线程进行上传或下载,如果碰到网络故障,可以从已经上传或下载的部分开始继续上传下载未完成的部分,而没有必要从头开始上传下载。用户可以节省时间,提高速度
一般实现方式有两种:
- 服务器端返回,告知从哪开始
- 浏览器端自行处理
上传过程中将文件在服务器写为临时文件,等全部写完了(文件上传完),将此临时文件重命名为正式文件即可
如果中途上传中断过,下次上传的时候根据当前临时文件大小,作为在客户端读取文件的偏移量,从此位置继续读取文件数据块,上传到服务器从此偏移量继续写入文件即可
计网
http与https的区别
http(HyperText Transfer Protocol),即超文本运输协议,是实现网络通信的一种规范。其传输的数据并不是计算机底层上的二进制包,而是完整的,有意义的数据,如HTML文件,图片文件,查询结果等超文本。能够被上层应用识别到。在实际的应用当中,http协议常用于Web浏览器与网站服务器之间传递消息,以明文方式发送内容,不提供任何方式的数据加密。- 特点:
- 支持客户/服务器模式。
- 简单快速:客户向服务器请求服务的时候,只需要传送请求方法和路径。由于
http协议简单,使得http服务器的程序规模小,因而通信速度很快。 - 灵活:
http允许传输任意类型的数据对象。正在传输的对象用Content-Type加以标记。 - 无连接:限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
- 无状态:
http协议无法根据之前的状态进行本次的请求处理。
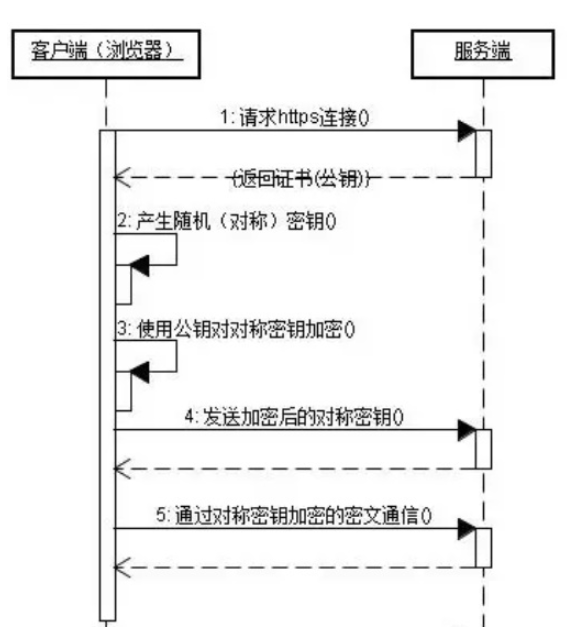
https,即运行在SSL/TLS上的http协议,SSL/TLS运行在TCP/IP协议与各种应用层协议之间。- 过程:
- 浏览器向使用
SSL/TLS的网站发送请求的时候,网站服务器会返回一个包含自己的公钥和身份信息的证书,这个证书通常是由可信任的机构颁发的。 - 浏览器会验证证书的有效性和真实性,如果证书合法,自己生成一段随机的对称密钥,并用公钥加密发送给服务端。
- 服务段用自己的私钥解密对称密钥,然后用这个对称密钥加密数据,实现加密通信。
- 浏览器段使用该对称密钥解密数据,显示在页面上。
- 这样,浏览器和网站之间的通信就是通过对称密钥加密的,第三方无法窃取或篡改数据,从而实现了安全通信。
- 浏览器向使用
- 过程:
https相对于http的优势
http的一些问题
- 使用明文通信,内容可能被窃听
- 不验证通信方的身份,因此有可能遭遇伪装。
https 为何更安全
- 对称加密:加密与解密所用的密钥都是同一个,如果保证了密钥的安全,那么就保证了通信的机密性。
- 非对称加密:密钥分为公钥和私钥,公钥加密只能用私钥解密,私钥加密只能用公钥解密。
- 混合加密:
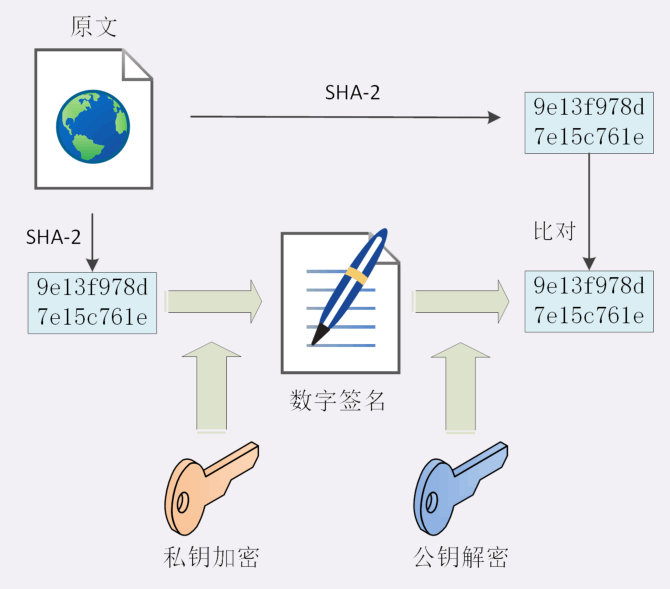
https采用的是对称加密+非对称加密,https采用非对称加密来解决密钥交换的问题。即浏览器使用公钥来加密对称密钥,服务端使用私钥来解密对称密钥,实现密钥的私密性。 - 摘要算法:通过摘要算法压缩数据,给数据生成独一无二的
ID,验证数据的完整性。 - 数字签名:将
ID用私钥加密,确保了消息确实由发送方发送出来的。
- CA 机构:使用 CA 公钥解密证书的数字签名,确保证书和公钥的有效性。
CA 对公钥的签名认证要求包括序列号、用途、颁发者、有效时间等等,把这些打成一个包再签名,完整地证明公钥关联的各种信息,形成“数字证书”
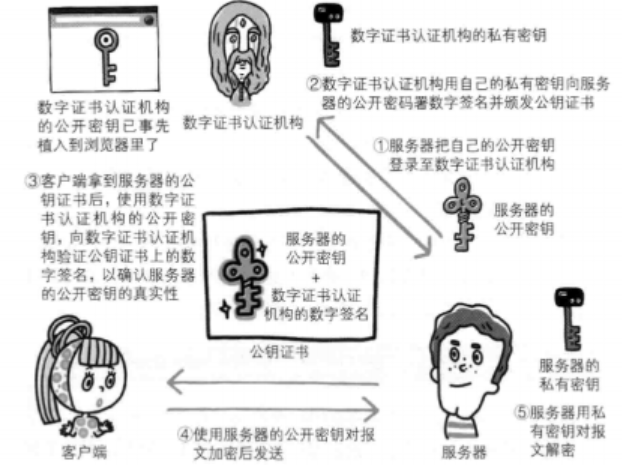
复杂请求的基本概念
复杂请求是指不满足简单请求条件的跨域请求。简单请求的条件是:
- 请求方法是 GET、POST 或 HEAD 之一
- 请求头只包含 Accept、Accept-Language、Content-Language 和 Content-Type 四种,且 Content-Type 的值只能是 text/plain、multipart/form-data 或 application/x-www-form-urlencoded 之一
- 请求中没有使用 XMLHttpRequestUpload 对象注册事件监听器,也没有使用 ReadableStream 对象
复杂请求在发送实际请求之前,需要先发送一个预检请求(preflight request),用 OPTIONS 方法向服务器询问是否允许该跨域请求。预检请求中包含以下两个特殊的请求头:
- Access-Control-Request-Method:表示实际请求的方法
- Access-Control-Request-Headers:表示实际请求的自定义头部
一个基本示例
1
2
3
4
5
6
7
8
9
OPTIONS /resources/post-here/ HTTP/1.1
Host: bar.example
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-us,en;q=0.5
Accept-Encoding: gzip,deflate
Connection: keep-alive
Origin: https://foo.example
Access-Control-Request-Method: POST
Access-Control-Request-Headers: X-PINGOTHER, Content-Type服务器根据预检请求中的信息,返回一个预检响应(preflight response),告诉浏览器是否允许该跨域请求。预检响应中包含以下几个重要的响应头:
- Access-Control-Allow-Origin:表示允许的请求来源,可以是具体的域名,也可以是*表示任意域名
- Access-Control-Allow-Methods:表示允许的请求方法,是一个以逗号分隔的列表
- Access-Control-Allow-Headers:表示允许的请求头,是一个以逗号分隔的列表
- Access-Control-Allow-Credentials:表示是否允许携带身份凭证(如 cookies),只能是 true 或者省略
- Access-Control-Max-Age:表示预检响应的有效时间,单位是秒
只有当预检响应中的 Access-Control-Allow-Origin 和实际请求的 Origin 相匹配,且 Access-Control-Allow-Methods 和 Access-Control-Allow-Headers 包含实际请求的方法和头部时,浏览器才会发送实际请求。否则,浏览器会报错,拒绝执行该跨域请求。
一个基本示例
1
2
3
4
5
6
7
8
9
10
HTTP/1.1 200 OK
Date: Mon, 01 Dec 2008 01:15:39 GMT
Server: Apache/2.0.61 (Unix)
Access-Control-Allow-Origin: https://foo.example
Access-Control-Allow-Methods: POST, GET, OPTIONS
Access-Control-Allow-Headers: X-PINGOTHER, Content-Type
Access-Control-Max-Age: 86400
Vary: Accept-Encoding, Origin
Keep-Alive: timeout=2, max=100
Connection: Keep-Alive原生方法对预检请求进行响应
使用原生方法对跨域请求的预检请求进行响应,需要在服务器端设置一些响应头,来告诉浏览器是否允许该请求,以及允许的方法、头部、凭证等。具体来说,有以下几个步骤:
- 首先,判断请求是否是跨域请求,可以通过检查请求头中的
Origin字段,如果该字段存在且不等于当前服务器的域名,说明是跨域请求。 - 其次,判断请求是否是预检请求,可以通过检查请求方法是否是
OPTIONS,如果是,说明是预检请求。 然后,根据业务逻辑,决定是否允许该跨域请求,如果允许,就在响应头中添加以下字段:
Access-Control-Allow-Origin: 表示允许的来源域,可以是具体的域名,也可以是*表示任意域名。Access-Control-Allow-Methods: 表示允许的请求方法,可以是多个,用逗号分隔,例如GET,POST,PUT,DELETE等。Access-Control-Allow-Headers: 表示允许的请求头,可以是多个,用逗号分隔,例如Content-Type,Authorization等。Access-Control-Max-Age: 表示预检请求的有效期,单位是秒,表示在这个时间内,不需要再发送预检请求。Access-Control-Allow-Credentials: 表示是否允许携带凭证,例如Cookie或HTTP认证,可以是true或false。
最后,返回响应,结束预检请求,浏览器会根据响应头中的信息,决定是否继续发送真正的请求。
下面是一个使用原生方法的 Node.js 代码示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
// 引入 http 模块
const http = require("http");
// 创建一个 http 服务器
const server = http.createServer(function (req, res) {
// 获取请求头中的 Origin 字段
const origin = req.headers.origin;
// 获取请求方法
const method = req.method;
// 判断是否是跨域请求
if (origin && origin !== "http://localhost:3000") {
// 判断是否是预检请求
if (method === "OPTIONS") {
// 设置响应头,允许跨域请求
res.setHeader("Access-Control-Allow-Origin", origin); // 允许任意域名跨域
res.setHeader("Access-Control-Allow-Methods", "GET, POST, PUT, DELETE"); // 允许的请求方法
res.setHeader(
"Access-Control-Allow-Headers",
"Content-Type, Authorization"
); // 允许的请求头
res.setHeader("Access-Control-Max-Age", "86400"); // 预检请求的有效期为一天
res.setHeader("Access-Control-Allow-Credentials", "true"); // 允许携带凭证
// 返回响应
res.end();
} else {
// 处理其他请求,例如 GET, POST 等
// ...
}
} else {
// 处理非跨域请求,例如本地请求
// ...
}
});
// 监听 3000 端口
server.listen(3000, function () {
console.log("Server is running on port 3000");
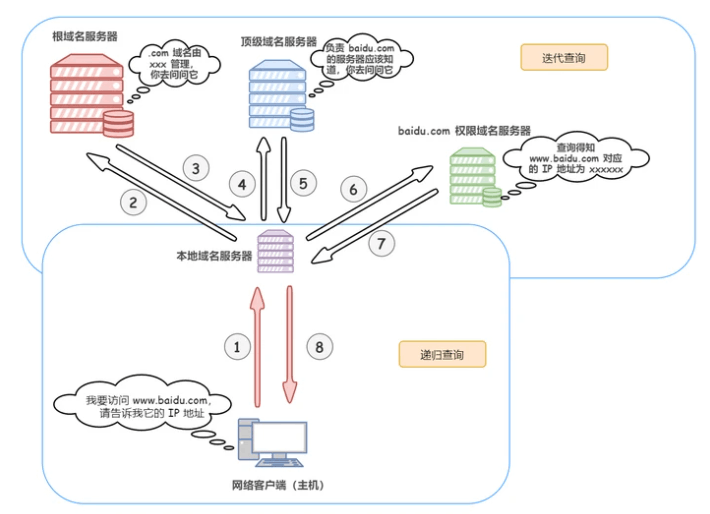
});DNS查询过程
- 查询浏览器 DNS 缓存。
- 查询操作系统 DNS 缓存。
- 查询本地域名服务器 DNS 缓存。
- 查询根域名服务器,返回顶级域名服务器。
- 本地服务器向顶级域名服务器发送查询请求,返回权限域名服务器的地址。
- 向权限域名服务器发送请求,获取 IP 地址。
- 获得 IP 地址形成访问。
CDN原理
CDN的基本原理:CDN的全称为Content Delivery Network,即内容分发网络,可作为网站的静态资源服务站点,用来减轻源站的网络请求压力。CDN的作用为返回离用户最近节点的资源,减轻源站网络请求压力,提升用户体验。CDN的工作流程为:- 浏览器请求
CDN链接,经过DNS解析流程,返回CNAME记录指向负载均衡系统。 - 负载均衡系统通过计算返回离用户最近的节点(即边缘节点)的
IP地址。 - 浏览器再向边缘节点发送请求获取静态资源。(注:DNS 解析记录的缓存一般只缓存第一次的解析结果,所以边缘节点的
IP地址一般不会被缓存这也与直觉相同。)
- 浏览器请求
衡量
CDN服务的指标- 命中率:用户访问的资源恰好在缓存系统里,可以直接返回给用户,命中次数与所有访问次数之比。
- 回源率:缓存里没有,必须用代理的方式回源站取,回源次数与所有访问次数之比。
缓存代理
缓存系统也可以划分出层次,分成一级缓存节点和二级缓存节点。一级缓存配置高一些,直连源站,二级缓存配置低一些,直连用户。回源的时候二级缓存只找一级缓存,一级缓存没有才回源站,可以有效地减少真正的回源。现在的商业CDN命中率都在90%以上,相当于把源站的服务能力放大了10倍以上。
UDP与TCP的简单理解,两个协议都位于 OSI 的传输层
UDP(User Datagram Protocol):是一个面向用户数据包的通信协议,即对应用层交下来的报文,不合并,不拆分,只是在其上面加上首部后就交给了下面的网络层。TCP(Transmission Control Protocol):是一种可靠的面向字节流的协议,可以想象成流水形式的,发送方 TCP 会将数据放入“蓄水池”(缓存区),等到可以发送的时候就发送,不能发送就等着,TCP 会根据当前网络的拥塞状态来确定每个报文段的大小。
HTTP/1.0/1.1/2.0
HTTP 1.0 和 HTTP 1.1 之间有哪些区别
连接方面,
http1.0默认使用非持久连接,而http1.1默认使用持久连接。http1.1通过使用持久连接来使多个http请求复用同一个TCP连接,以此来避免使用非持久连接时每次需要建立连接的时延。资源请求方面,在
http1.0中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,http1.1则在请求头引入了range头域,它允许只请求资源的某个部分,即返回码是206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。缓存方面,在
http1.0中主要使用header里的If-Modified-Since、Expires来做为缓存判断的标准,http1.1则引入了更多的缓存控制策略,例如Etag、If-Unmodified-Since、If-Match、If-None-Match等更多可供选择的缓存头来控制缓存策略。- http1.1 中新增了 host 字段,用来指定服务器的域名。
http1.0中认为每台服务器都绑定一个唯一的IP地址,因此,请求消息中的URL并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机,并且它们共享一个IP地址。因此有了host字段,这样就可以将请求发往到同一台服务器上的不同网站。 - http1.1 相对于
http1.0还新增了很多请求方法,如PUT、HEAD、OPTIONS等。
HTTP 1.1 和 HTTP 2.0 之间有哪些区别
二进制协议:
HTTP/2是一个二进制协议。在HTTP/1.1版中,报文的头信息必须是文本(ASCII 编码),数据体可以是文本,也可以是二进制。HTTP/2则是一个彻底的二进制协议,头信息和数据体都是二进制,并且统称为”帧”,可以分为头信息帧和数据帧。多个帧之间可以乱序发送,根据帧首部的流标识可以重新组装,这也是多路复用同时发送数据的实现条件。多路复用:
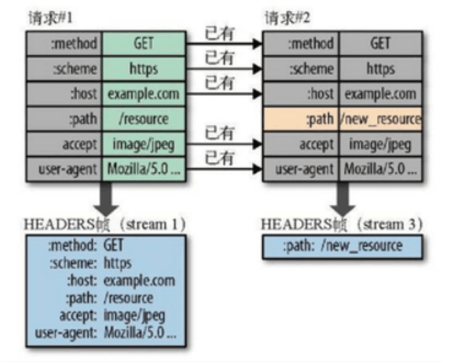
HTTP/2实现了多路复用,HTTP/2仍然复用TCP连接,但是在一个连接里,客户端和服务器都可以同时发送多个请求或回应,而且不用按照顺序一一发送,这样就避免了”队头堵塞”的问题。数据流:
HTTP/2使用了数据流的概念,因为HTTP/2的数据包是不按顺序发送的,同一个连接里面连续的数据包,可能属于不同的请求。因此,必须要对数据包做标记,指出它属于哪个请求。HTTP/2将每个请求或回应的所有数据包,称为一个数据流。每个数据流都有一个独一无二的编号。数据包发送时,都必须标记数据流ID,用来区分它属于哪个数据流。头信息压缩:
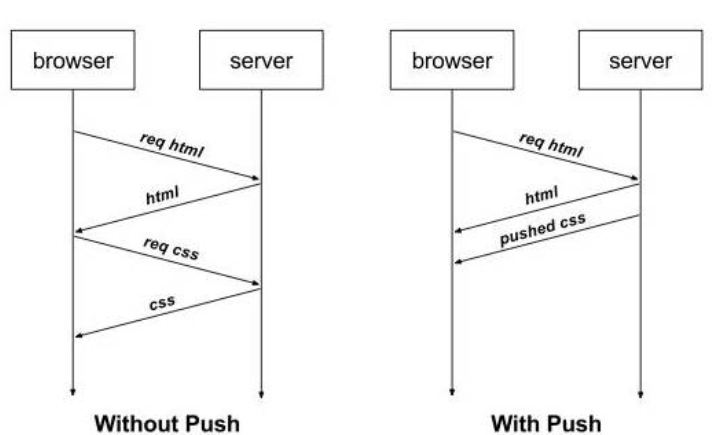
HTTP/2实现了头信息压缩,由于HTTP 1.1协议不带状态,每次请求都必须附上所有信息。所以,请求的很多字段都是重复的,比如Cookie和User Agent,一模一样的内容,每次请求都必须附带,这会浪费很多带宽,也影响速度。HTTP/2对这一点做了优化,引入了头信息压缩机制,头信息表充当状态。一方面,头信息使用gzip或compress压缩后再发送;另一方面,客户端和服务器同时维护一张头信息表,所有字段都会存入这个表,生成一个索引号,以后就不发送同样字段了,只发送索引号,这样就能提高速度了。- 服务器推送:
HTTP/2允许服务器未经请求,主动向客户端发送资源,这叫做服务器推送。使用服务器推送提前给客户端推送必要的资源,这样就可以相对减少一些延迟时间。这里需要注意的是http2下服务器主动推送的是静态资源,和WebSocket以及使用SSE等方式向客户端发送即时数据的推送是不同的。
队头阻塞的概念:队头阻塞是由
HTTP基本的“请求 - 应答”模型所导致的。HTTP规定报文必须是“一发一收”,这就形成了一个先进先出的“串行”队列。队列里的请求是没有优先级的,只有入队的先后顺序,排在最前面的请求会被最优先处理。如果队首的请求因为处理的太慢耽误了时间,那么队列里后面的所有请求也不得不跟着一起等待,结果就是其他的请求承担了不应有的时间成本,造成了队头堵塞的现象。
HTTP常用状态码
100:服务器已收到请求,需进一步响应。101:用于http和websocket协议升级。200:常规资源请求成功。201:请求成功并在服务端创建了新的资源。301:重定向。302:临时移动。400:错误请求。401:未授权。502:错误网关。503:服务不可用。
协商缓存
举个例子,假设客户端第一次请求一个图片文件,服务器返回 200 OK 的状态码,以及图片的内容,同时在响应头中设置了 Last-Modified: Wed, 10 Nov 2021 07:00:51 GMT 和 Etag: "1234567890",表示该图片的最后修改时间和唯一标识。客户端会将这些信息和图片一起缓存到本地。当客户端再次请求该图片时,会在请求头中添加 If-Modified-Since: Wed, 10 Nov 2021 07:00:51 GMT 和 If-None-Match: "1234567890",表示只有当图片在这个时间之后被修改过,或者图片的标识发生变化时,才需要重新获取图片。如果服务器检查发现图片没有变化,就会返回 304 Not Modified 的状态码,不会返回图片的内容,客户端就可以直接使用本地缓存的图片。如果服务器检查发现图片有变化,就会返回 200 OK 的状态码,以及新的图片内容,客户端就会更新本地缓存,并显示新的图片。
URL 跳转网站发生了什么
URL解析DNS查询TCP连接- 发出
HTTP请求 - 响应请求
- 页面渲染

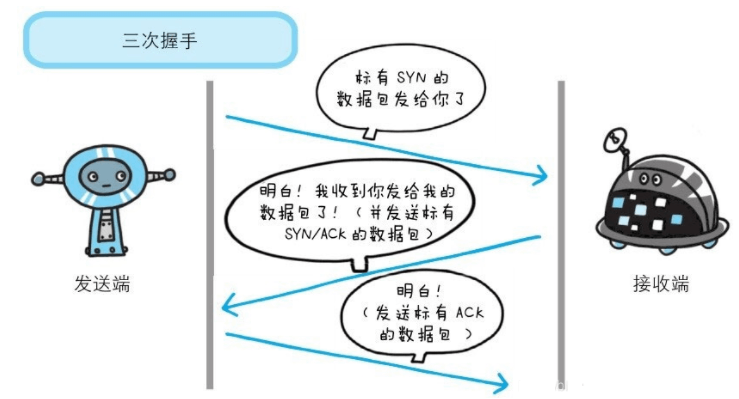
WebSocket
WebSocket 是一种在单个 TCP 连接上进行全双工通信的协议,它使得浏览器和服务器之间可以实现实时双向的数据交换。WebSocket 的优点是:
- 可以减少服务器的资源和带宽消耗,提高通信效率和性能。
- 可以实现服务端主动推送数据给客户端,不需要客户端频繁地轮询服务器。
- 可以支持多种数据格式,包括文本、二进制、图像、音频、视频等。
- 可以兼容多种浏览器和平台,只要支持
HTML5的浏览器都可以使用WebSocket。
WebSocket 的工作流程如下:
- 客户端向服务器发起一个
HTTP请求,请求头中包含一个Upgrade字段,表示要升级协议为WebSocket。 - 服务器收到请求后,如果同意升级,就会返回一个
HTTP响应,响应头中包含一个Upgrade字段,表示已经切换到WebSocket协议。 - 客户端和服务器之间建立一个
WebSocket连接,之后就可以通过这个连接进行双向的数据传输。 - 客户端或服务器可以随时关闭连接,发送一个关闭帧,然后断开
TCP连接。
WebSocket 的使用方法如下:
- 在
JavaScript中,可以使用WebSocket对象来创建和管理一个WebSocket连接,以及发送和接收数据。WebSocket对象的构造函数接受一个参数,即服务器的 URL,例如var socket = new WebSocket("ws://example.com")。 WebSocket对象有以下几个属性:socket.readyState:表示连接的当前状态,有四种可能的值:0(连接尚未建立),1(连接已经建立,可以通信),2(连接正在关闭),3(连接已经关闭或者连接失败)。socket.url:表示连接的绝对 URL。socket.protocol:表示服务器选择的子协议,如果没有选择,就是空字符串。socket.binaryType:表示二进制数据的类型,可以是blob或者arraybuffer。socket.bufferedAmount:表示还有多少字节的数据没有发送出去,可以用来判断发送是否结束。
WebSocket对象有以下几个方法:socket.send(data):向服务器发送数据,可以是文本或者二进制数据。socket.close(code, reason):关闭连接,可以指定一个数字的状态码和一个字符串的原因。
WebSocket对象有以下几个事件:open:当连接建立时触发,可以使用socket.onopen属性或者socket.addEventListener("open", handler)方法来监听。message:当收到服务器的数据时触发,可以使用socket.onmessage属性或者socket.addEventListener("message", handler)方法来监听。事件对象有一个data属性,表示收到的数据,可以是文本或者二进制数据。error:当发生错误时触发,可以使用socket.onerror属性或者socket.addEventListener("error", handler)方法来监听。事件对象没有提供错误的具体信息,只能通过socket.readyState来判断连接的状态。close:当连接关闭时触发,可以使用socket.onclose属性或者socket.addEventListener("close", handler)方法来监听。事件对象有三个属性:code表示关闭的状态码,reason表示关闭的原因,wasClean表示是否是正常关闭。
Node.js
Node.js 的优点与缺点
优点:
- 处理高并发场景性能更佳。
- 适合 I/O 密集型应用,值的是应用在运行极限时,CPU 占用率仍然比较低,大部分时间是在做 I/O 硬盘内存读写操作。
因为Node.js单线程所带来的缺点
- 不适合 CPU 密集型应用。
- 只支持单核 CPU,不能充分利用 CPU。
- 可靠性低,一旦代码的某个环节崩溃,整个系统都会崩溃。
Node.js 的常见全局对象。
全局对象分为两类:
- 真正的全局对象
- 模块的全局变量
真正的全局对象
BufferglobalsetTimeout, setInterval, clearTimeout, clearIntervalprocessconsole
模块级别的全局变量
__dirname:当前文件所在的路径,不包括后面的文件名。__filename:当前文件所在的路径与名称,包括文件的名称。exportsmodulerequire
Node.js中的process对象
process.env:获取不同环境项目的配置信息。process.pid:获取当前进程的pid。process.ppid:获取当前进程对应的父进程。process.cwd():获得当前进程的工作目录。process.platform:获得当前运行进程的操作系统平台。process.uptime():获得当前进程已运行的时间。process.on('uncaughtException', cb)捕获异常信息、process.on('exit', cb)进程退出监听。- 三个标准流
process.stdin、process.stdout和process.stderr。 process.title:指定进程名称。process.argv:传入的命令行参数。
Node.js中的fs模块
writeFile/writeFileSyncappendFile/appendFileSynccreateWriteStreamreadFile/readFileSynccreateReadStreamrename/renameSyncunlink/unlinkSyncmkdir/mkdirSyncreaddir/readdirSyncrmdir/rmdirSyncstat/statSynccopyfile/copyfileSync
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
//将 『三人行,必有我师焉。』 写入到当前文件夹下的『座右铭.txt』文件中
fs.writeFile("./座右铭.txt", "三人行,必有我师焉。", (err) => {
//如果写入失败,则回调函数调用时,会传入错误对象,如写入成功,会传入 null
if (err) {
console.log(err);
return;
}
console.log("写入成功");
});
fs.writeFileSync("2.txt", "Hello world");
let data = fs.readFileSync("2.txt", "utf8");
console.log(data); // Hello world
fs.appendFile("3.txt", " world", (err) => {
if (!err) {
fs.readFile("3.txt", "utf8", (err, data) => {
console.log(data); // Hello world
});
}
});
fs.appendFileSync("3.txt", " world");
let data = fs.readFileSync("3.txt", "utf8");
let ws = fs.createWriteStream("./观书有感.txt");
ws.write("半亩方塘一鉴开\r\n");
ws.write("天光云影共徘徊\r\n");
ws.write("问渠那得清如许\r\n");
ws.write("为有源头活水来\r\n");
ws.end();
fs.readFile("1.txt", "utf8", (err, data) => {
if (!err) {
console.log(data); // Hello
}
});
let buf = fs.readFileSync("1.txt");
let data = fs.readFileSync("1.txt", "utf8");
console.log(buf); // <Buffer 48 65 6c 6c 6f>
console.log(data); // Hello
//创建读取流对象
let rs = fs.createReadStream("./观书有感.txt");
//每次取出 64k 数据后执行一次 data 回调
rs.on("data", (data) => {
console.log(data);
console.log(data.length);
});
//读取完毕后, 执行 end 回调
rs.on("end", () => {
console.log("读取完成");
});
fs.rename("./观书有感.txt", "./论语/观书有感.txt", (err) => {
if (err) throw err;
console.log("移动完成");
});
fs.renameSync("./座右铭.txt", "./论语/我的座右铭.txt");
fs.unlink("./test.txt", (err) => {
if (err) throw err;
console.log("删除成功");
});
fs.unlinkSync("./test2.txt");
fs.mkdir("./page", (err) => {
if (err) throw err;
console.log("创建成功");
});
//递归异步创建
fs.mkdir("./1/2/3", { recursive: true }, (err) => {
if (err) throw err;
console.log("递归创建成功");
});
//递归同步创建文件夹
fs.mkdirSync("./x/y/z", { recursive: true });
//异步读取
fs.readdir("./论语", (err, data) => {
if (err) throw err;
console.log(data);
});
//同步读取
let data = fs.readdirSync("./论语");
console.log(data);
//异步删除文件夹
fs.rmdir("./page", (err) => {
if (err) throw err;
console.log("删除成功");
});
//异步递归删除文件夹
fs.rmdir("./1", { recursive: true }, (err) => {
if (err) {
console.log(err);
}
console.log("递归删除");
});
//同步递归删除文件夹
fs.rmdirSync("./x", { recursive: true });
//异步获取状态
fs.stat("./data.txt", (err, data) => {
if (err) throw err;
console.log(data);
});
//同步获取状态
let data = fs.statSync("./data.txt");
fs.copyFileSync("3.txt", "4.txt");
let data = fs.readFileSync("4.txt", "utf8");
console.log(data); // Hello world
fs.copyFile("3.txt", "4.txt", () => {
fs.readFile("4.txt", "utf8", (err, data) => {
console.log(data); // Hello world
});
});Buffer
Buffer(缓冲区)是Node.js用于表示固定长度的字节序列,本质上是一段内存空间,专门用来处理二进制数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
//创建了一个长度为 10 字节的 Buffer,相当于申请了 10 字节的内存空间,每个字节的值为 0
let buf_1 = Buffer.alloc(10); // 结果为 <Buffer 00 00 00 00 00 00 00 00 00 00>
//创建了一个长度为 10 字节的 Buffer,buffer 中可能存在旧的数据, 可能会影响执行结果,所以叫
// unsafe
let buf_2 = Buffer.allocUnsafe(10);
//通过字符串创建 Buffer
let buf_3 = Buffer.from("hello");
//通过数组创建 Buffer
let buf_4 = Buffer.from([105, 108, 111, 118, 101, 121, 111, 117]);
let buf_4 = Buffer.from([105, 108, 111, 118, 101, 121, 111, 117]);
console.log(buf_4.toString());
const buffer = Buffer.from("你好", "utf-8 ");
console.log(buffer);
// <Buffer e4 bd a0 e5 a5 bd>
const str = buffer.toString("ascii");
console.log(str);
// d= e%=IO的stream流进行管道读写
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
const fs = require("fs");
const inputStream = fs.createReadStream("input.txt"); // 创建可读流
const outputStream = fs.createWriteStream("output.txt"); // 创建可写流
inputStream.pipe(outputStream); // 管道读写
// 文件操作
const path = require("path");
// 两个文件名
const fileName1 = path.resolve(__dirname, "data.txt");
const fileName2 = path.resolve(__dirname, "data-bak.txt");
// 读取文件的 stream 对象
const readStream = fs.createReadStream(fileName1);
// 写入文件的 stream 对象
const writeStream = fs.createWriteStream(fileName2);
// 通过 pipe执行拷贝,数据流转
readStream.pipe(writeStream);
// 数据读取完成监听,即拷贝完成
readStream.on("end", function () {
console.log("拷贝完成");
});Node.js 中的 EventEmitter
手写实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
class EventEmitter {
constructor() {
this.callbacks = {};
}
addListener(type, handler) {
if (!this.callbacks[type]) {
this.callbacks[type] = [];
}
this.callbacks[type].push(handler);
}
on(type, handler) {
this.addListener(type, handler);
}
prependListener(type, handler) {
if (!this.callbacks[type]) {
this.callbacks[type] = [];
}
this.callbacks[type].unshift(handler);
}
emit(type, ...args) {
this.callbacks[type].forEach((callback) =>
Reflect.apply(callback, this, args)
);
}
removeListener(type, handler) {
const index = this.callbacks[type].findIndex(
(callback) => callback === handler
);
this.callbacks[type].splice(index, 1);
}
off(type, handler) {
this.removeListener(type, handler);
}
once(type, handler) {
this.addListener(type, this._onceWrap(handler, type));
}
_onceWrap(handler, type) {
let isFired = false;
const wrapFUnc = function (...args) {
if (!isFired) {
Reflect.apply(handler, this, args);
isFired = true;
this.removeListener(type, wrapFUnc);
}
};
return wrapFUnc;
}
}
const ee = new EventEmitter();
// 注册所有事件
ee.once("wakeUp", (name) => {
console.log(`${name} 1`);
});
ee.on("eat", (name) => {
console.log(`${name} 2`);
});
ee.on("eat", (name) => {
console.log(`${name} 3`);
});
const meetingFn = (name) => {
console.log(`${name} 4`);
};
ee.on("work", meetingFn);
ee.on("work", (name) => {
console.log(`${name} 5`);
});
ee.emit("wakeUp", "xx");
ee.emit("wakeUp", "xx"); // 第二次没有触发
ee.emit("eat", "xx");
ee.emit("work", "xx");
ee.off("work", meetingFn); // 移除事件
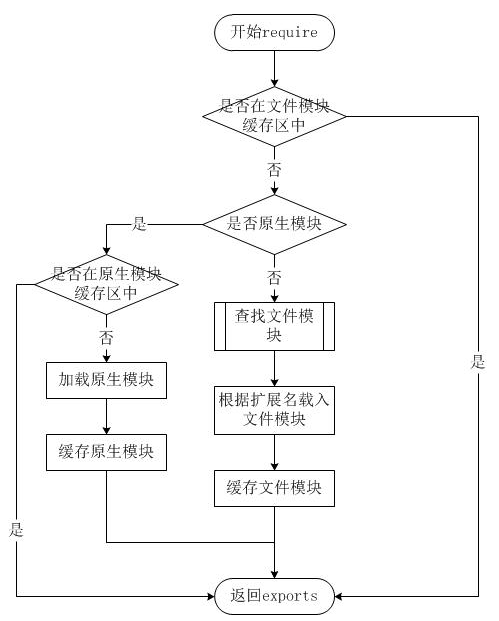
ee.emit("work", "xx"); // 再次工作Node.js 模块加载流程
从上图可以看见,文件模块存在缓存区,寻找模块路径的时候都会优先从缓存中加载已经存在的模块
在模块中使用 require 传入文件路径即可引入文件require 使用的一些注意事项:
- 缓存的模块优先级最高
- 如果是内置模块,则直接返回,优先级仅次缓存的模块
- 如果是绝对路径
/开头,则从根目录找 - 如果是相对路径
./开头,则从当前require文件相对位置找 - 如果文件没有携带后缀,先从
js、json、node按顺序查找 - 如果是目录,则根据
package.json的main属性值决定目录下入口文件,默认情况为index.js - 如果文件为第三方模块,则会引入
node_modules文件,如果不在当前仓库文件中,则自动从上级递归查找,直到根目录
koa 洋葱模型
koa 是一个基于 node.js 的轻量级的 web 框架,它使用了一种独特的中间件执行流程,被称为洋葱模型。洋葱模型指的是以 next()函数为分割点,先由外到内执行请求的逻辑,再由内到外执行响应的逻辑。通过洋葱模型,可以实现中间件之间的通信和协作,以及优雅的错误处理。koa 的洋葱模型的实现主要依赖于 async/await 和 Promise 的特性,以及一个名为koa-compose 的库,它可以将多个中间件组合成一个函数,然后按照顺序执行。
洋葱模型的核心思想是,每个中间件都会接收两个参数:ctx 和 next。ctx 是一个封装了请求和响应的对象,可以通过它来获取或修改请求和响应的信息。next 是一个函数,它表示下一个要执行的中间件。每个中间件都可以选择调用或不调用 next,从而控制中间件栈的执行流程。如果调用了 next,那么当前中间件会暂停执行,等待下一个中间件执行完毕后,再继续执行当前中间件的剩余部分。如果没有调用 next,那么当前中间件就是最后一个执行的中间件,之后的中间件都不会执行。
这样的设计使得中间件可以实现类似于洋葱的层层包裹的效果,每个中间件都可以在请求进入时和响应返回时执行一些操作,而且可以访问或修改前面或后面中间件所添加或修改的信息。这样可以实现很多功能,比如日志记录、错误处理、身份验证、路由匹配、数据缓存等等。
下面是一个简单的例子,演示了洋葱模型的执行过程:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
// 引入koa模块
const Koa = require("koa");
// 创建一个koa实例
const app = new Koa();
// 定义一个中间件,打印请求的方法和路径
app.use(async (ctx, next) => {
console.log(`请求方法:${ctx.method},请求路径:${ctx.path}`);
// 调用next,进入下一个中间件
await next();
// 当下一个中间件执行完毕后,继续执行当前中间件的后续逻辑
console.log("第一个中间件结束");
});
// 定义一个中间件,模拟一个异步操作,比如数据库查询
app.use(async (ctx, next) => {
console.log("开始异步操作");
// 使用setTimeout模拟一个耗时的异步操作
await new Promise((resolve) => setTimeout(resolve, 1000));
// 异步操作完成后,调用next,进入下一个中间件
await next();
// 当下一个中间件执行完毕后,继续执行当前中间件的后续逻辑
console.log("异步操作结束");
});
// 定义一个中间件,设置响应的内容和状态码
app.use(async (ctx) => {
console.log("设置响应");
// 设置响应内容
ctx.body = "Hello Koa";
// 设置响应状态码
ctx.status = 200;
// 没有调用next,表示响应已经结束,不需要执行后面的中间件
});
// 监听3000端口
app.listen(3000, () => {
console.log("服务器启动成功,监听在3000端口");
});当我们访问http://localhost:3000时,可以在控制台看到如下的输出:
1
2
3
4
5
请求方法:GET,请求路径:/
开始异步操作
设置响应
异步操作结束
第一个中间件结束可以看到,中间件的执行顺序是:
- 第一个中间件的前半部分
- 第二个中间件的前半部分
- 第三个中间件的全部
- 第二个中间件的后半部分
- 第一个中间件的后半部分
JWT
JWT(JSON Web Token),本质就是一个字符串书写规范,如下图,作用是用来在用户和服务器之间传递安全可靠的信息
Token,分成了三个部分Header、Payload和Signature。Header:个JWT都会带有头部信息,这里主要声明使用的算法。声明算法的字段名为alg,同时还有一个typ的字段,默认JWT即可。以下示例中算法为HS2561
2{ "alg": "HS256", "typ": "JWT" } // base64URL 编码 后 eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9Payload:载荷即消息体,这里会存放实际的内容,也就是Token的数据声明,例如用户的id和name,默认情况下也会携带令牌的签发时间iat,通过还可以设置过期时间,如下:- ss (issuer):签发人
- exp (expiration time):过期时间
- sub (subject):主题
- aud (audience):受众
- nbf (Not Before):生效时间
- iat (Issued At):签发时间
- jti (JWT ID):编号
1
2
3
4
5
6{ "sub": "1234567890", "name": "John Doe", "iat": 1516239022 } // base64URL 编码后 eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiaWF0IjoxNTE2MjM5MDIyfQSignature:签名是对头部和载荷内容进行签名,一般情况,设置一个secretKey,对前两个的结果进行HMACSHA25算法,这里计算完毕后不需要用base64URL再进行编码,公式如下:1
2
3
4Signature = HMACSHA256( base64Url(header) + "." + base64Url(payload), secretKey );
生成
Token1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48const crypto = require("crypto"), jwt = require("jsonwebtoken"); // TODO:使用数据库 // 这里应该是用数据库存储,这里只是演示用 let userList = []; class UserController { // 用户登录 static async login(ctx) { const data = ctx.request.body; if (!data.name || !data.password) { return (ctx.body = { code: "000002", message: "参数不合法", }); } const result = userList.find( (item) => item.name === data.name && item.password === crypto.createHash("md5").update(data.password).digest("hex") ); if (result) { // 生成token const token = jwt.sign( { name: result.name, }, "test_token", // secret { expiresIn: 60 * 60 } // 过期时间:60 * 60 s ); return (ctx.body = { code: "0", message: "登录成功", data: { token, }, }); } else { return (ctx.body = { code: "000002", message: "用户名或密码错误", }); } } } module.exports = UserController;校验
Token1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29// 导入 jwt 模块 const jwt = require("jsonwebtoken"); // 导入 config 模块 const { SECRET } = require("../config/config"); module.exports = (req, res, next) => { // 校验 token let token = req.get("token"); // 判断 if (!token) { return res.json({ code: "2003", msg: "token 缺失", data: null, }); } // 校验 token jwt.verify(token, SECRET, (err, data) => { // 检测 token 是否正确 if (err) { return res.json({ code: "2004", msg: "token校验失败", data: null, }); } req.user = data; next(); }); };

版本控制系统
版本管理及其工具
- 本地版本控制系统
- 优点:
- 简单,很多系统都有内置。
- 适合管理文本,如配置文件。
- 缺点:
- 其不支持远程操作,因此不适合多人版本开发。
- 优点:
集中式版本管理系统
- 优点:
- 适合多人团队协作开发。
- 代码集中化管理
- 缺点:
- 单点故障
- 必须联网,无法单击工作
代表工具:
SVN,CVS。- 优点:
分布式版本控制系统
优点:- 适合多人团队协作开发。
- 代码集中化管理。
- 可以离线工作。
- 每个计算机都是一个完整的仓库。
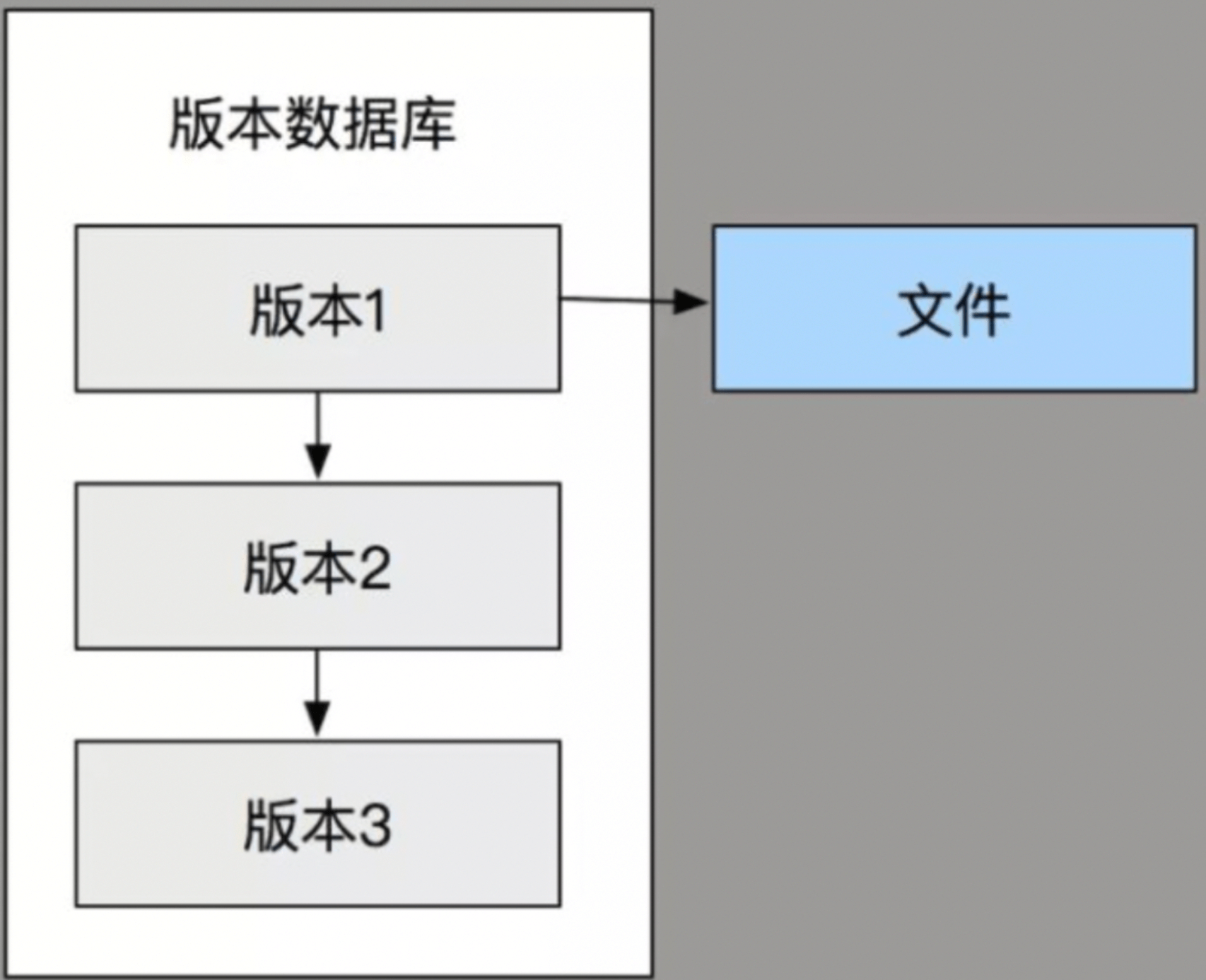
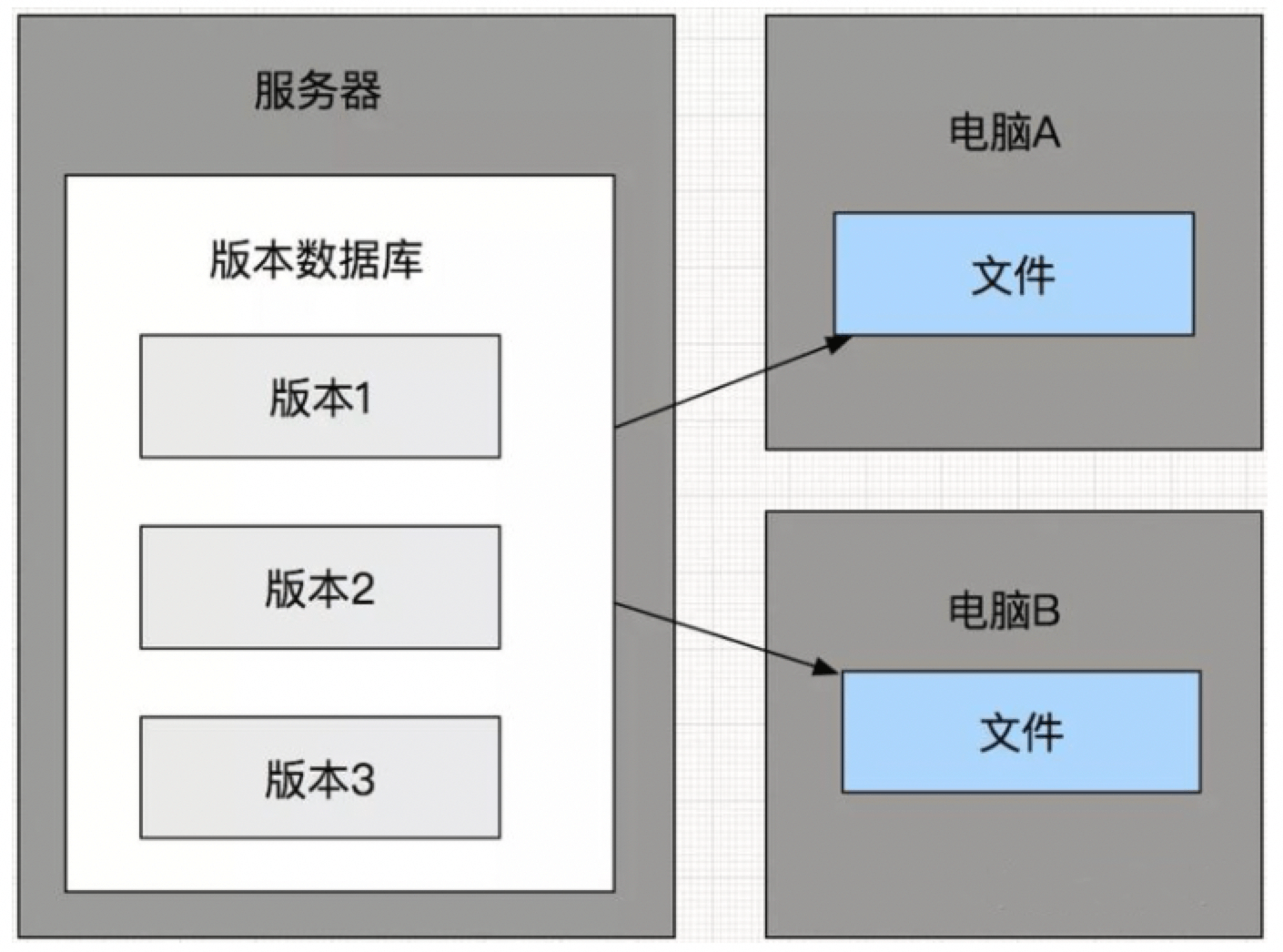
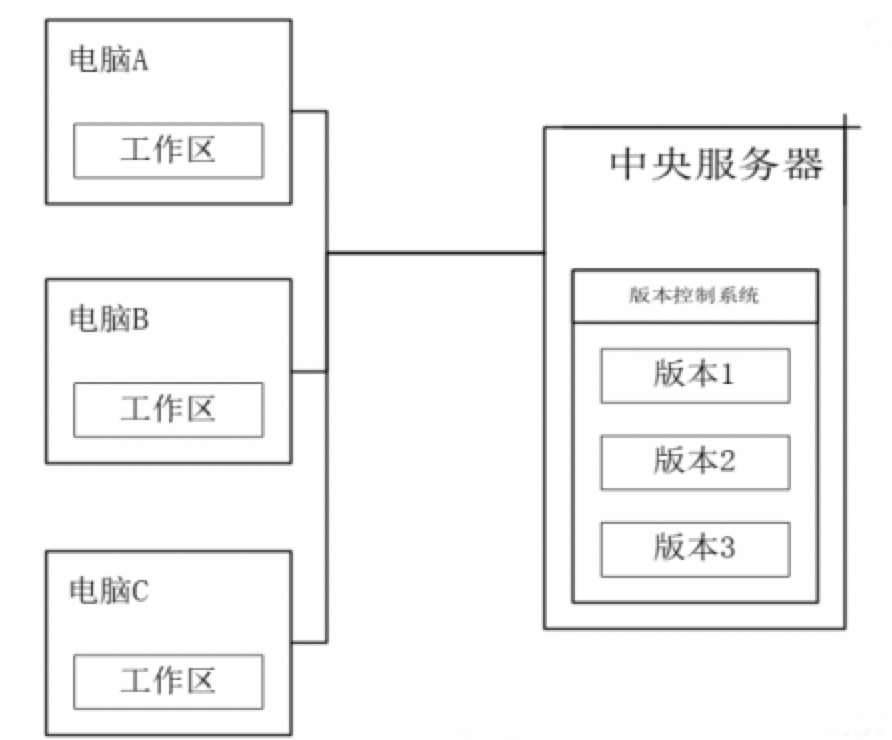
对于git命令的详细说明,请参考 Git 笔记。
操作系统
对操作系统的基本理解
- 操作系统是管理计算机硬件与软件资源的程序,是计算机的基石。
- 操作系统本质上是一个运行在计算机上的软件程序 ,用于管理计算机硬件和软件资源。
- 操作系统存在屏蔽了硬件层的复杂性。 操作系统就像是硬件使用的负责人,统筹着各种相关事项。
- 操作系统的内核(
Kernel)是操作系统的核心部分,它负责系统的内存管理,硬件设备的管理,文件系统的管理以及应用程序的管理。 内核是连接应用程序和硬件的桥梁,决定着系统的性能和稳定性。
进程与线程
- 进程:进程是系统进行资源分配和调度的基本单位。
进程一般由三部分组成:程序,数据集和进程控制块。- 程序用于描述进程要完成的功能,是控制进程执行的指令集。
- 数据集合是程序在执行时所需要的数据和工作区。
- 程序控制块,包含进程的描述信息和控制信息,是进程存在的唯一标志。
- 线程:是操作系统能够进行运算调度的最小单位。
线程是当前进程中的一个执行任务(执行单元),负责当前进程中程序的执行。
软链接与硬链接
软链接和硬链接是Linux文件系统中两种不同的链接方式,它们的区别和用途如下:
- 软链接(也叫符号链接)是一种特殊的文件,它包含了另一个文件的路径名。软链接可以看作是一个快捷方式,它可以指向任意的文件或目录,无论它们是否存在或在哪个文件系统中。软链接的文件属性中有一个
l标志,表示它是一个链接文件。软链接的创建和删除不会影响原文件或目录的内容和状态。 - 硬链接是一种为文件创建多个名字的方式,它们共享同一个索引节点(
inode),也就是说,它们指向同一个文件的数据块。硬链接的文件属性中没有l标志,它们和原文件没有区别。硬链接的创建和删除不会影响文件的数据和引用计数,只有当所有的硬链接都被删除后,文件才会被真正删除。
在Windows系统中,也有类似的概念,但是有一些不同之处:
Windows系统中的快捷方式相当于Linux中的软链接,它们都是一个指向目标文件或目录的文件,可以放在任何位置,可以有不同的名称和图标,可以添加参数和备注,可以通过属性查看和修改。但是,Windows系统中的快捷方式是以.lnk为扩展名的二进制文件,而Linux中的软链接是以目标文件的路径名为内容的文本文件。Windows系统中的硬链接和Linux中的硬链接类似,它们都是指向同一个文件的多个名字,它们的文件属性和内容都相同,它们的创建和删除不会影响文件的数据和引用计数。但是,Windows系统中的硬链接只能在同一个卷中创建,不能跨分区或跨磁盘,而Linux中的硬链接只能在同一个文件系统中创建,不能跨文件系统。Windows系统中还有一种叫做符号链接(Symbolic Link)的链接方式,它和Linux中的软链接类似,但是有一些区别。Windows系统中的符号链接可以是文件或目录,可以跨分区或跨磁盘,可以指向本地或网络的目标,可以通过属性查看和修改。但是,Windows系统中的符号链接需要管理员权限才能创建,需要特殊的命令或工具才能创建,需要特殊的标志才能识别,需要特殊的处理才能删除。
设计模式
基本概念
在软件工程中,设计模式是对软件设计中普遍存在的各种问题所提出的解决方案。设计模式并不直接用来完成代码的编写,而是描述在各种不同情况下,要怎么解决问题的一种方案。设计模式能使不稳定依赖于相对稳定、具体依赖于相对抽象,避免会引起麻烦的紧耦合,以增强软件设计面对并适应变化的能力。
常用的设计模式
- 单例模式
- 工厂模式
- 策略模式
- 代理模式
- 中介者模式
- 装饰者模式
单例模式(Singleton)
单例模式(Singleton Pattern):创建型模式,提供了一种创建对象的最佳方式,这种模式涉及到一个单一的类,该类负责创建自己的对象,同时确保只有单个对象被创建。核心为只创建一次,后续只使用这个创建的对象。
采用类的静态方法与静态变量进行创建。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25// 定义一个类 function Singleton(name) { this.name = name; this.instance = null; } // 原型扩展类的一个方法getName() Singleton.prototype.getName = function () { console.log(this.name); }; // 获取类的实例 Singleton.getInstance = function (name) { if (!this.instance) { this.instance = new Singleton(name); } return this.instance; }; // 获取对象1 const a = Singleton.getInstance("a"); // 获取对象2 const b = Singleton.getInstance("b"); // 进行比较 console.dir(Singleton); console.log(a, b); console.log(a === b);采用闭包
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26function Singleton(name) { this.name = name; } // 原型扩展类的一个方法getName() Singleton.prototype.getName = function () { console.log(this.name); }; // 获取类的实例 Singleton.getInstance = (function () { var instance = null; return function (name) { if (!instance) { instance = new Singleton(name); } return instance; }; })(); // 获取对象1 const a = Singleton.getInstance("a"); // 获取对象2 const b = Singleton.getInstance("b"); // 进行比较 console.dir(Singleton); console.log(a, b); console.log(a === b);使用函数表达式写成一个构造函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27// 单例构造函数 function CreateSingleton(name) { this.name = name; this.getName(); } // 获取实例的名字 CreateSingleton.prototype.getName = function () { console.log(this.name); }; // 单例对象 const Singleton = (function () { var instance; return function (name) { if (!instance) { instance = new CreateSingleton(name); } return instance; }; })(); // 创建实例对象 1 const a = new Singleton("a"); // 创建实例对象 2 const b = new Singleton("b"); console.log(a === b); // true
工厂模式(Factory)
工厂模式是用来创建对象的一种最常用的设计模式,不暴露创建对象的具体逻辑,而是将将逻辑封装在一个函数中,那么这个函数就可以被视为一个工厂。
适用场景:
- 编程中,在一个
A类中通过new的方式实例化了类B,那么A类和B类之间就存在关联(耦合) - 后期因为需要修改了
B类的代码和使用方式,比如构造函数中传入参数,那么A类也要跟着修改,一个类的依赖可能影响不大,但若有多个类依赖了B类,那么这个工作量将会相当的大,容易出现修改错误,也会产生很多的重复代码,这无疑是件非常痛苦的事; - 这种情况下,就需要将创建实例的工作从调用方(
A类)中分离,与调用方解耦,也就是使用工厂方法创建实例的工作封装起来(减少代码重复),由工厂管理对象的创建逻辑,调用方不需要知道具体的创建过程,只管使用,而降低调用者因为创建逻辑导致的错误;
简单工厂模式(Simple Factory)
简单工厂模式也叫静态工厂模式,用一个工厂对象创建同一类对象类的实例1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29function Factory(career) { function User(career, work) { this.career = career; this.work = work; } let work; switch (career) { case "coder": work = ["写代码", "修Bug"]; return new User(career, work); break; case "hr": work = ["招聘", "员工信息管理"]; return new User(career, work); break; case "driver": work = ["开车"]; return new User(career, work); break; case "boss": work = ["喝茶", "开会", "审批文件"]; return new User(career, work); break; } } let coder = new Factory("coder"); console.log(coder); let boss = new Factory("boss"); console.log(boss);工厂方法模式
工厂方法模式是一种创建型设计模式,它定义了一个接口或抽象类,用于创建对象,但让子类决定要实例化哪个类。工厂方法让类将实例化的过程延迟到子类。
工厂方法模式跟简单工厂模式差不多,但是把具体的产品放到了工厂函数的prototype中。这样一来,扩展产品种类就不必修改工厂函数了,核心就变成抽象类,也可以随时重写某种具体的产品,也就是相当于工厂总部不生产产品了,交给下辖分工厂进行生产;但是进入工厂之前,需要有个判断来验证你要生产的东西是否是属于我们工厂所生产范围,如果是,就丢给下辖工厂来进行生产。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32// 工厂方法 function Factory(career) { if (this instanceof Factory) { var a = new this[career](); return a; } else { return new Factory(career); } } // 工厂方法函数的原型中设置所有对象的构造函数 Factory.prototype = { coder: function () { this.careerName = "程序员"; this.work = ["写代码", "修Bug"]; }, hr: function () { this.careerName = "HR"; this.work = ["招聘", "员工信息管理"]; }, driver: function () { this.careerName = "司机"; this.work = ["开车"]; }, boss: function () { this.careerName = "老板"; this.work = ["喝茶", "开会", "审批文件"]; }, }; let coder = new Factory("coder"); console.log(coder); let hr = new Factory("hr"); console.log(hr);1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85// 抽象的Animal类 class Animal { constructor(name, sound, food) { this.name = name; this.sound = sound; this.food = food; } // 抽象的create方法,由子类实现 create() { throw new Error("Abstract method!"); } // 打印动物的信息 printInfo() { console.log( `This is a ${this.name}, it says ${this.sound}, and it eats ${this.food}.` ); } } // Lion类,继承自Animal class Lion extends Animal { constructor() { super("lion", "roar", "meat"); } // 实现create方法,返回自己的实例 create() { return new Lion(); } } // Tiger类,继承自Animal class Tiger extends Animal { constructor() { super("tiger", "growl", "meat"); } // 实现create方法,返回自己的实例 create() { return new Tiger(); } } // Panda类,继承自Animal class Panda extends Animal { constructor() { super("panda", "bleat", "bamboo"); } // 实现create方法,返回自己的实例 create() { return new Panda(); } } // Zoo类,用于管理动物 class Zoo { constructor() { this.animals = []; // 存储动物的数组 } // 添加动物的方法,接收一个Animal类型的参数,并调用其create方法,将创建的动物实例添加到数组中 addAnimal(animal) { if (animal instanceof Animal) { this.animals.push(animal.create()); } else { throw new Error("Invalid animal!"); } } } // 创建一个Zoo的实例 let zoo = new Zoo(); // 向Zoo中添加不同种类的动物 zoo.addAnimal(new Lion()); zoo.addAnimal(new Tiger()); zoo.addAnimal(new Panda()); // 遍历Zoo的数组,打印每个动物的信息 for (let animal of zoo.animals) { animal.printInfo(); }抽象工厂模式
抽象工厂模式是一种创建型设计模式,它可以让我们创建一系列相关或相互依赖的对象,而无需指定它们具体的类。抽象工厂模式可以提高代码的可扩展性和可维护性,因为它可以将对象的创建和使用分离,降低了类之间的耦合度。抽象工厂模式的主要角色有以下四个:
- 抽象工厂(
Abstract Factory):它是一个接口或抽象类,用于声明一组创建不同类型对象的方法。 - 具体工厂(
Concrete Factory):它是抽象工厂的子类,用于实现抽象工厂中声明的方法,创建具体的对象。 - 抽象产品(
Abstract Product):它是一个接口或抽象类,用于定义一类产品的公共属性和方法。 - 具体产品(
Concrete Product):它是抽象产品的子类,用于实现抽象产品中定义的属性和方法,表示具体的产品实例。
在JavaScript中,我们可以使用函数来实现抽象工厂模式。具体实现步骤如下: - 创建一个抽象工厂函数,用于创建一系列相关的对象。
- 在抽象工厂函数中,创建一个对象字典,用于存储不同类型的对象。
- 在对象字典中,为每种类型的对象创建一个工厂函数,用于创建该类型的对象。
- 在抽象工厂函数中,创建一个工厂选择器函数,用于根据传入的参数选择相应的工厂函数。
- 在工厂函数中,创建具体的对象,并返回该对象。
以下是使用
JS实现的抽象工厂模式的一个例子,它模拟了一个电脑商店,有不同品牌和类型的电脑,每种电脑都有自己的价格和性能。我们定义了一个抽象的Computer类,它有一个抽象的create方法,用于创建具体的电脑实例。我们还定义了几个继承自Computer的子类,如Dell, Lenovo, Asus等,它们都实现了自己的create方法,用于返回自己的实例。我们还定义了一个ComputerStore类,它有一个getComputer方法,用于接收一个Computer类型的参数,并调用其create方法,将创建的电脑实例返回给客户。最后,我们创建了一个ComputerStore的实例,并向其请求了不同品牌和类型的电脑,然后打印出每个电脑的信息。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121// 抽象的Computer类 class Computer { constructor(brand, type, price, performance) { this.brand = brand; this.type = type; this.price = price; this.performance = performance; } // 抽象的create方法,由子类实现 create() { throw new Error("Abstract method!"); } // 打印电脑的信息 printInfo() { console.log( `This is a ${this.brand} ${this.type}, it costs ${this.price}, and it has ${this.performance} performance.` ); } } // Dell类,继承自Computer class Dell extends Computer { constructor(type) { super("Dell", type); } // 实现create方法,根据type返回不同的实例 create() { switch (this.type) { case "laptop": return new Dell("laptop", 5000, "high"); case "desktop": return new Dell("desktop", 3000, "medium"); default: throw new Error("Invalid type!"); } } } // Lenovo类,继承自Computer class Lenovo extends Computer { constructor(type) { super("Lenovo", type); } // 实现create方法,根据type返回不同的实例 create() { switch (this.type) { case "laptop": return new Lenovo("laptop", 4000, "medium"); case "desktop": return new Lenovo("desktop", 2000, "low"); default: throw new Error("Invalid type!"); } } } // Asus类,继承自Computer class Asus extends Computer { constructor(type) { super("Asus", type); } // 实现create方法,根据type返回不同的实例 create() { switch (this.type) { case "laptop": return new Asus("laptop", 6000, "high"); case "desktop": return new Asus("desktop", 4000, "high"); default: throw new Error("Invalid type!"); } } } // ComputerStore类,用于管理电脑 class ComputerStore { constructor() { this.computers = {}; // 存储电脑的对象字典 } // 添加电脑的方法,接收一个Computer类型的参数,并将其添加到对象字典中 addComputer(computer) { if (computer instanceof Computer) { this.computers[computer.brand] = computer; } else { throw new Error("Invalid computer!"); } } // 获取电脑的方法,接收一个brand和type的参数,并根据对象字典中的工厂函数,创建并返回相应的电脑实例 getComputer(brand, type) { if (this.computers[brand]) { return this.computers[brand].create(type); } else { throw new Error("No such brand!"); } } } // 创建一个ComputerStore的实例 let store = new ComputerStore(); // 向ComputerStore中添加不同品牌的电脑 store.addComputer(new Dell()); store.addComputer(new Lenovo()); store.addComputer(new Asus()); // 从ComputerStore中获取不同品牌和类型的电脑 let dellLaptop = store.getComputer("Dell", "laptop"); let lenovoDesktop = store.getComputer("Lenovo", "desktop"); let asusLaptop = store.getComputer("Asus", "laptop"); // 打印电脑的信息 dellLaptop.printInfo(); lenovoDesktop.printInfo(); asusLaptop.printInfo();输出结果为:
1
2
3This is a Dell laptop, it costs 5000, and it has high performance. This is a Lenovo desktop, it costs 2000, and it has low performance. This is a Asus laptop, it costs 6000, and it has high performance.这个例子展示了抽象工厂模式的优点,它可以让我们在不修改抽象工厂的情况下,增加新的具体工厂和具体产品,实现多态性和灵活性。同时,它也可以让我们将对象的创建和使用分离,降低了代码的耦合度。
- 抽象工厂(
策略模式(Strategy)
策略模式(Strategy Pattern)指的是定义一系列的算法,把它们一个个封装起来,目的就是将算法的使用与算法的实现分离开来
一个基于策略模式的程序至少由两部分组成:
- 策略类,策略类封装了具体的算法,并负责具体的计算过程
- 环境类
Context,Context接受客户的请求,随后 把请求委托给某一个策略类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
// 抽象的Operator类
class Operator {
constructor(symbol) {
this.symbol = symbol;
}
// 抽象的calculate方法,由子类实现
calculate(num1, num2) {
throw new Error("Abstract method!");
}
}
// Add类,继承自Operator
class Add extends Operator {
constructor() {
super("+");
}
// 实现calculate方法,返回两个数的和
calculate(num1, num2) {
return num1 + num2;
}
}
// Subtract类,继承自Operator
class Subtract extends Operator {
constructor() {
super("-");
}
// 实现calculate方法,返回两个数的差
calculate(num1, num2) {
return num1 - num2;
}
}
// Multiply类,继承自Operator
class Multiply extends Operator {
constructor() {
super("*");
}
// 实现calculate方法,返回两个数的积
calculate(num1, num2) {
return num1 * num2;
}
}
// Divide类,继承自Operator
class Divide extends Operator {
constructor() {
super("/");
}
// 实现calculate方法,返回两个数的商
calculate(num1, num2) {
if (num2 === 0) {
throw new Error("Divide by zero!");
}
return num1 / num2;
}
}
// Calculator类,用于管理运算符
class Calculator {
constructor() {
this.operator = null; // 存储当前的运算符
}
// 设置运算符的方法,接收一个Operator类型的参数,并将其保存为当前的运算符
setOperator(operator) {
if (operator instanceof Operator) {
this.operator = operator;
} else {
throw new Error("Invalid operator!");
}
}
// 获取计算结果的方法,接收两个数作为参数,并调用当前运算符的calculate方法,将计算结果返回给用户
getResult(num1, num2) {
if (this.operator) {
return this.operator.calculate(num1, num2);
} else {
throw new Error("No operator!");
}
}
}
// 创建一个Calculator的实例
let calculator = new Calculator();
// 向Calculator中设置不同的运算符
calculator.setOperator(new Add());
calculator.setOperator(new Subtract());
calculator.setOperator(new Multiply());
calculator.setOperator(new Divide());
// 调用Calculator的getResult方法,得到不同的计算结果
console.log(calculator.getResult(10, 5)); // 2
console.log(calculator.getResult(20, 10)); // 2
console.log(calculator.getResult(3, 4)); // 0.75
console.log(calculator.getResult(6, 2)); // 3代理模式(Proxy)
代理模式是一种结构型设计模式,它可以让我们为一个对象创建一个替代对象,用来控制对原对象的访问。代理对象和原对象有相同的接口,这样就可以在不影响原对象功能的情况下,增加一些额外的操作,如验证、缓存、延迟等。代理模式的优点是可以提高代码的可扩展性和可维护性,降低原对象的复杂度和耦合度,遵循单一职责原则。
在JavaScript中,我们可以使用ES6的Proxy类来实现代理模式。Proxy类可以接收两个参数,一个是目标对象,一个是处理器对象。处理器对象可以定义一些拦截器函数,用来拦截目标对象的属性和方法的访问,从而实现代理的功能。
以下是一个使用JavaScript实现的代理模式的一个例子,它模拟了一个用户登录的场景,有一个User类,用来表示用户的信息,如用户名和密码。我们定义了一个ProxyUser类,用来作为User类的代理,它接收一个User对象作为参数,并创建一个Proxy对象,用来拦截User对象的login方法,增加一些验证和日志的操作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
// User类,用来表示用户的信息
class User {
constructor(username, password) {
this.username = username;
this.password = password;
}
// login方法,用来模拟用户登录的逻辑
login() {
console.log(`${this.username} is logging in...`);
// some login logic
console.log(`${this.username} logged in successfully!`);
}
}
// ProxyUser类,用来作为User类的代理
class ProxyUser {
constructor(user) {
// 创建一个Proxy对象,用来拦截user对象的login方法
this.proxy = new Proxy(user, {
// 定义一个拦截器函数,用来在调用login方法之前和之后执行一些操作
apply: function (target, thisArg, argumentsList) {
// 在调用login方法之前,验证用户名和密码是否合法
if (target.username && target.password) {
// 调用login方法
target.login.apply(thisArg, argumentsList);
// 在调用login方法之后,记录日志
console.log(`Log: ${target.username} logged in at ${new Date()}`);
} else {
// 如果用户名或密码不合法,抛出错误
throw new Error("Invalid username or password!");
}
},
});
}
}
// 创建一个User对象
let user = new User("Alice", "123456");
// 创建一个ProxyUser对象,传入User对象作为参数
let proxyUser = new ProxyUser(user);
// 通过ProxyUser对象的proxy属性,调用User对象的login方法
proxyUser.proxy();输出结果为:
1
2
3
Alice is logging in...
Alice logged in successfully!
Log: Alice logged in at Fri Nov 26 2021 16:11:23 GMT+0800 (中国标准时间)观察者模式(Observer)
观察者模式定义了对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都将得到通知,并自动更新。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
class Subject {
constructor() {
this.observerList = [];
}
addObserver(observer) {
this.observerList.push(observer);
}
removeObserver(observer) {
const index = this.observerList.findIndex((o) => o.name === observer.name);
this.observerList.splice(index, 1);
}
notifyObservers(message) {
const observers = this.observerList;
observers.forEach((observer) => observer.notified(message));
}
}
class Observer {
constructor(name, subject) {
this.name = name;
if (subject) {
subject.addObserver(this);
}
}
notified(message) {
console.log(this.name, "got message", message);
}
}
const subject = new Subject();
const observerA = new Observer("observerA", subject);
const observerB = new Observer("observerB");
subject.addObserver(observerB);
subject.notifyObservers("Hello from subject");
subject.removeObserver(observerA);
subject.notifyObservers("Hello again");发布订阅模式(Pub/Sub)
发布-订阅是一种消息范式,消息的发送者(称为发布者)不会将消息直接发送给特定的接收者(称为订阅者)。而是将发布的消息分为不同的类别,无需了解哪些订阅者(如果有的话)可能存在
同样的,订阅者可以表达对一个或多个类别的兴趣,只接收感兴趣的消息,无需了解哪些发布者存在
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
class PubSub {
constructor() {
this.messages = {};
this.listeners = {};
}
// 添加发布者
publish(type, content) {
const existContent = this.messages[type];
if (!existContent) {
this.messages[type] = [];
}
this.messages[type].push(content);
}
// 添加订阅者
subscribe(type, cb) {
const existListener = this.listeners[type];
if (!existListener) {
this.listeners[type] = [];
}
this.listeners[type].push(cb);
}
// 通知
notify(type) {
const messages = this.messages[type];
const subscribers = this.listeners[type] || [];
subscribers.forEach((cb, index) => cb(messages[index]));
}
}
class Publisher {
constructor(name, context) {
this.name = name;
this.context = context;
}
publish(type, content) {
this.context.publish(type, content);
}
}
class Subscriber {
constructor(name, context) {
this.name = name;
this.context = context;
}
subscribe(type, cb) {
this.context.subscribe(type, cb);
}
}
const TYPE_A = "music";
const TYPE_B = "movie";
const TYPE_C = "novel";
const pubsub = new PubSub();
const publisherA = new Publisher("publisherA", pubsub);
publisherA.publish(TYPE_A, "we are young");
publisherA.publish(TYPE_B, "the silicon valley");
const publisherB = new Publisher("publisherB", pubsub);
publisherB.publish(TYPE_A, "stronger");
const publisherC = new Publisher("publisherC", pubsub);
publisherC.publish(TYPE_C, "a brief history of time");
const subscriberA = new Subscriber("subscriberA", pubsub);
subscriberA.subscribe(TYPE_A, (res) => {
console.log("subscriberA received", res);
});
const subscriberB = new Subscriber("subscriberB", pubsub);
subscriberB.subscribe(TYPE_C, (res) => {
console.log("subscriberB received", res);
});
const subscriberC = new Subscriber("subscriberC", pubsub);
subscriberC.subscribe(TYPE_B, (res) => {
console.log("subscriberC received", res);
});
pubsub.notify(TYPE_A);
pubsub.notify(TYPE_B);
pubsub.notify(TYPE_C);